
Continuing a drive to make its artificial intelligence models more accessible, Google LLC today announced the next generation of its lightweight open-source family of Gemma large language models that can run on a single graphics processing unit.
The new Gemma 3 models come in a range of sizes allowing developers to choose among 1 billion, 4 billion, 12 billion and 27 billion parameters. These ranges permit AI engineers and developers to pick the best model for the hardware and performance needs. For example, if it will be running on a GPU or tensor processing unit – allowing for a larger more complex model – or a smartphone – requiring a tiny model.
The technology underlying Gemma shares the same technical research as Google’s Gemini model, which is the most complex and powerful model the company has produced to date. Gemini powers the Gemini AI chatbot, formerly named Bard, which is available on the web and mobile devices and is also used to deliver many of Google’s AI-based services.
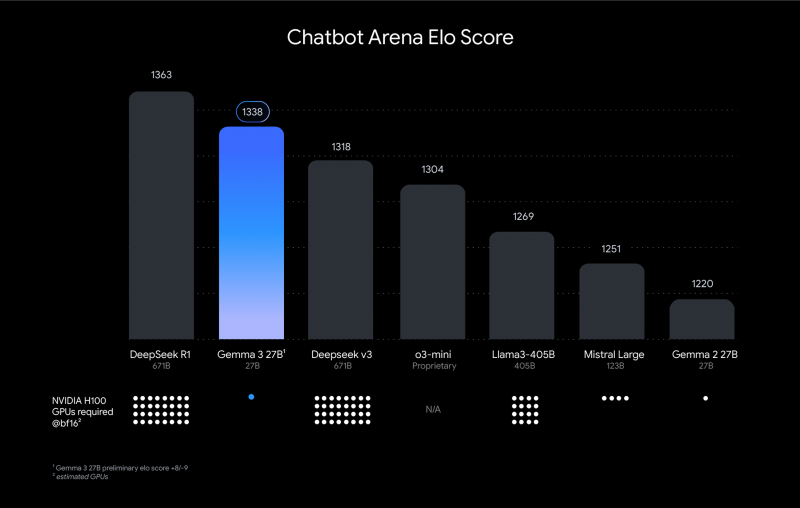
With this technical design, Google said Gemma 3 is capable of delivering high performance for its size, outperforming larger models such as Llama-405B, DeepSeek-V3 and OpenAI’s o3-mini in preliminary human preference evaluations on the LMArena leaderboard.
Even when run on a single device or GPU, Gemma still provides enough power for developers to create AI applications with multimodal capabilities with advanced text and visual reasoning. It has a 128,000-token context window, which means it can handle around 30 high-resolution images, a 300-page book or an hour or more of video. This is comparable to the context length of OpenAI’s GPT-4o.
Google said the model family includes function-calling and tool-use capabilities that will enable developers to automate tasks and build AI agents. In combination with the large context window, Gemma 3 will be able to ingest large amounts of data and automate complex sequential tasks.
Alongside Gemma 3, Google also announced ShieldGemma 2, a 4 billion-parameter variant that can check images for safety and label them as safe or dangerous.
SheildGemma enables developers to build applications that can examine uploaded images for potentially hazardous content. It outputs safety labels across three different categories such as “dangerous content,” “sexually explicit” and “violence.”
Developers using it in their applications can further tailor the model for their needs by providing content to watch for and label. Its weights and parameters are also open source so it can be trained for different industry needs and controls.
Images: Pixabay, Google
Your vote of support is important to us and it helps us keep the content FREE.
One click below supports our mission to provide free, deep, and relevant content.
Join our community on YouTube
Join the community that includes more than 15,000 #CubeAlumni experts, including Amazon.com CEO Andy Jassy, Dell Technologies founder and CEO Michael Dell, Intel CEO Pat Gelsinger, and many more luminaries and experts.
THANK YOU

